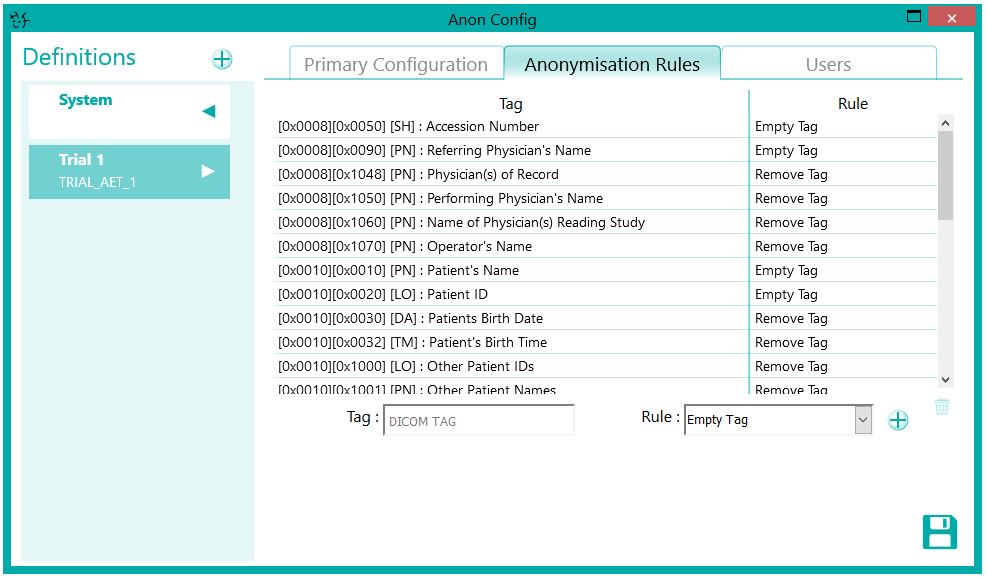
The DICOM anonymiser operates on the header information in the DICOM files as they pass through the node. Specific anonymisation rules can be configured based on the called AET, referred to as the “Trial AET” within the anonymiser.
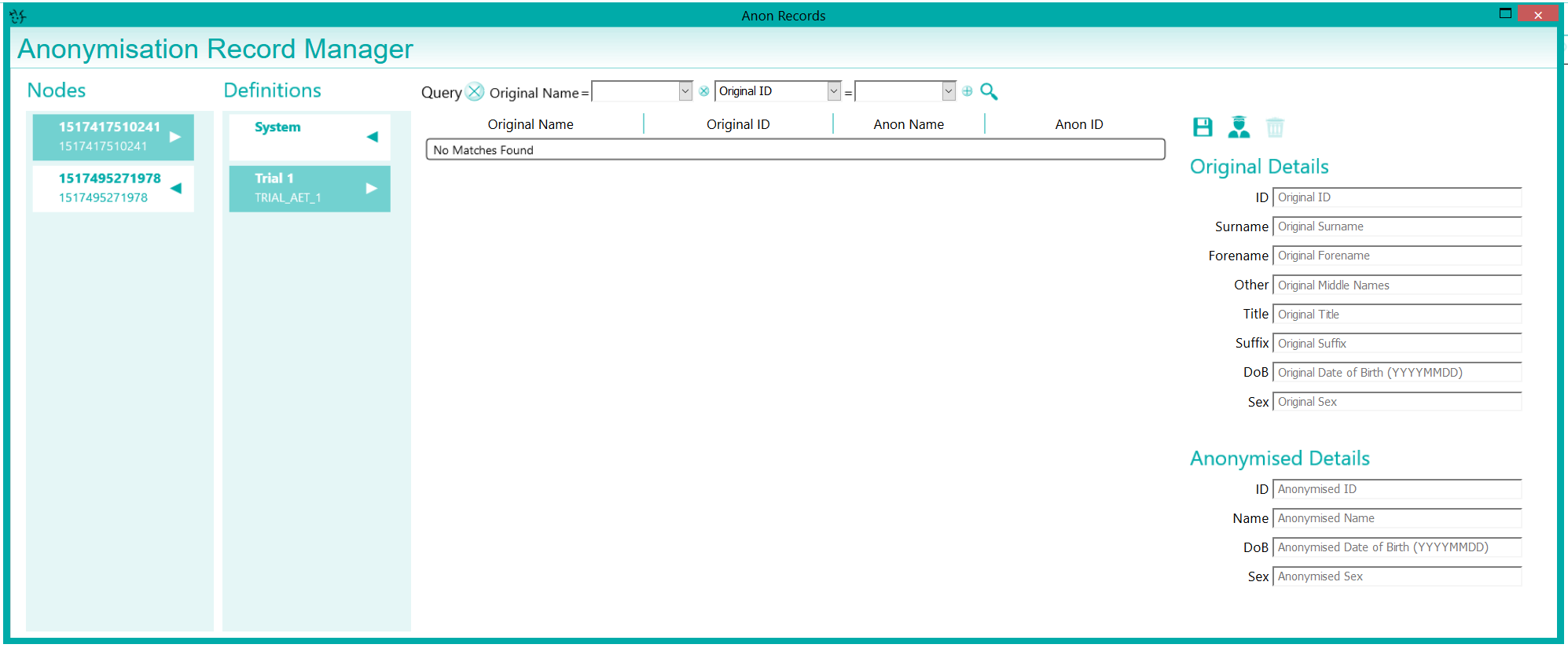
A key feature of the DICOM Anonymiser Node is the ability for it to build up an anonymous patient record, that is, if multiple studies for the same patient are sent to the same trial, they will be anonymised consistently across all the studies and therefore will show as a full history for the new anonymous record. Because some systems may have had the original data, if they receive the anonymised data with the original UIDs unchanged, then it is possible the original demographic data will be displayed by such a system as it has cached those details for the original UIDs. This is handled by the anonymiser by selecting to re-UID the DICOM header. A record is kept of the original and new UIDs as a look-up. This allows any cross-referencing using UIDs between DICOM files to be maintained, such that, if the system finds a UID it has replaced for the selected trial in the past, it uses the same one again. This allows DICOM objects such as RTPLANs to maintain a reference to an anonymised CT series, even after UIDs have been replaced.
The anonymisation node is in itself, a pseudonymisation process in that a record of the original is recorded in the database. This allows records to be predefined as part of a clinical trial or to be looked up. It also allows the de-anonymisation (re-identification) of data passing back through a Nexus pipeline. This is useful if the data needs to be anonymised before going off-site to be processed but needs to receive results from the processing back into the original record. By sending through an anonymisation node on the way out and a de-anonymisation node back in, the result can be reconciled with the original details but the processing system will only have ever interacted with an anonymised version of the data.
The last image shows an example network of how a DICOM object can be de-identified when passing from one DICOM system to the next and then it, or a derived DICOM object can be re-identified when passing back into the Nexus service.
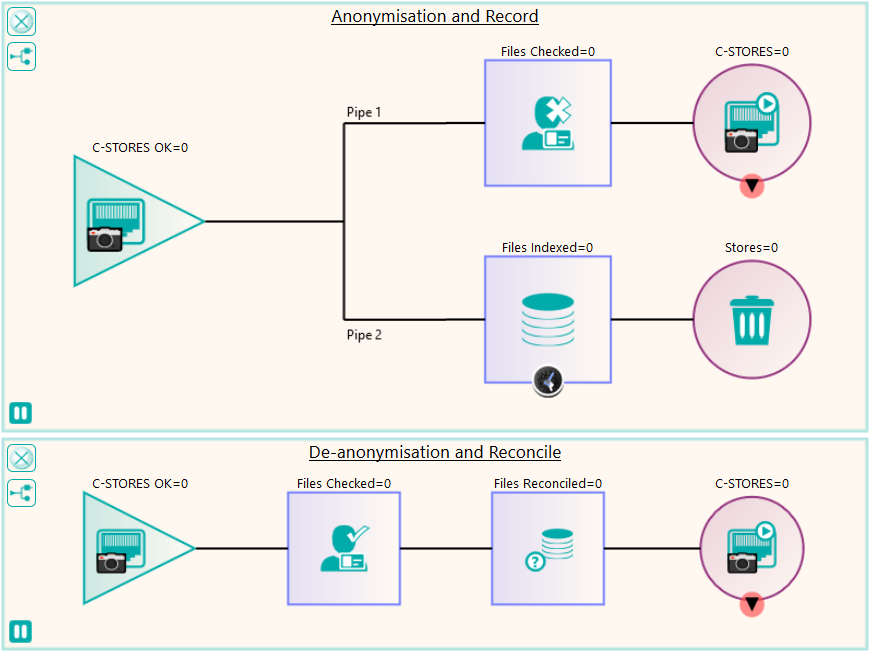
When data is sent to the external system, the anonymisation service keeps track of the anonymised primary demographics and any UIDs that are changed. If study level information needs to be restored as part of the re-identification, the original details for the objects should be recorded in a database node. This is shown in the top network above, where the database node is in the second branch below the anonymisation node. A splitter is used because it makes a copy of the original information. If the database was placed in-line with the anonymisation node, the anonymised data would be recorded in the database. The original files don’t need to be stored locally, so the output from the database node is just a terminator (dev null). The output from the anonymisation node is the external system that requires the anonymised data.
When a result needs to be returned to the original study, the DICOM object should be sent to the input node of the second network shown in the bottom of the figure. This network shows the data passing first through the de-anonymisation node which restores the primary demographics and the UIDs and secondly through a reconciliation node which restores study level attributes such as Accession Number, Study ID, Study Date, Study Time that may need to match the original study in order for a successful import to the originating system to occur.